

最近は、人工知能AIを活用し、コンピューターに画像や動画を判別してもらうことが増えてきています。そこで、画像分類(Image Classification)と物体検知(Object Detection)を実際にテストしましたので、簡単にご紹介したいと思います。
私自身、最近、画像分類と物体検知を試しているのですが、当初、自分のやりたいことには、どっちの方が適しているのか分かりませんでした。最終的には、不良判別のためでしたので、物体検知を選択しましたが、皆様にもそれぞれの特徴を知って頂き、より良き選択をして頂けたらと思います。
画像分類 Image Classification
まず初めに、画像分類を実際に行ってみました。
AIが覚えた画像と比較して、どの種類の画像に近いかを判断するため、物体が画像中のどこにあるかを判別しませんし、また、判定結果は1つしか出力されません。つまりのところ、複数の判別対象を画像内(動画内)に映し出しても結果は1つしか返してくれません。
画像分類モデルの作り方
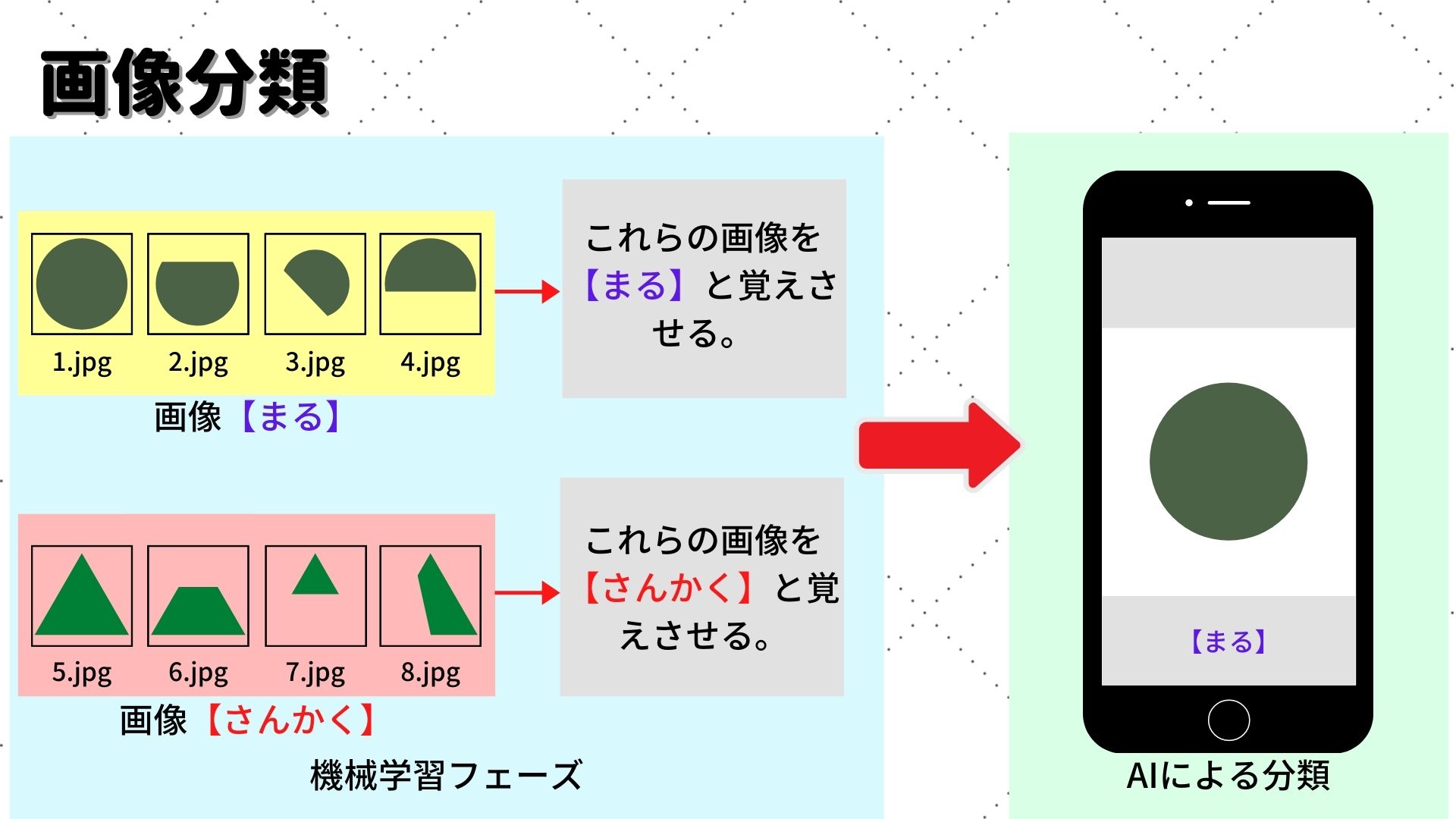
上記の【まる】と【さんかく】の画像を例にすると、機械学習フェーズで、【まる】という特徴のある画像を1つのフォルダに集めます。同様に【さんかく】という特徴のある画像を1つのフォルダに集めます。この2つに分けたフォルダを元に機械学習させると、【まる】と【さんかく】を判別するAIが出来上がります。細かいことは省略しますが、イメージとしてはこのような感じです。
そして、機械学習で作成したAIを、視覚的に見やすいように画像分類のプログラムに組み込むことで、結果を出力します。
画像分類という名前ですが、静止画だけでなく動画も分類可能です。理由としては、AIは画像としと捉えて分類していますが、例えば0.3秒に1回画像分類を実行すれば、見た目には、リアルタイムで映像を分類しているようにプログラムすることができます。
画像分類モデルを作成してみての感想
モデルの準備時間が短い。準備した写真を、特徴毎にフォルダに分けて保存すれば良いだけ。
トレーニング時間が短い。トレーニングの仕方は、いろいろありますが、Azureのcustum visionで1時間トレーニングを行うと、4種類の似た製品の分類が高い精度で完成しました。
物体検知 Object Detection
物体検知も動画にしてみました。
AIが覚えた特徴と比較して、どの種類の特徴に近いかを判断します。画像(あるいは動画)内から特徴を探すため、画像分類とは異なり、複数の物体を同時に判別することができます。
物体検知モデルの作り方
上記の画像を例にすると、機械学習フェーズで、画像の中から、【まる】の特徴を囲みタグ付けします。同様に【さんかく】の特徴も囲みタグ付けします。タグの付いた部分の特徴しかAIは覚えませんから、1枚の画像の中に【まる】と【さんかく】が混ざっていても問題ありません。タグが準備できたら、トレーニングを行い、物体検知のモデルが出来上がります。
そして、機械学習で作成したAIを、視覚的に見やすいように物体検知のプログラムに組み込むことで、結果を出力します。上記のように、1つの画面内に、物体の位置と名前を出力してくれます。
物体検知モデルを作成してみての感想
モデル作成時間が長い。タグ付け作業がとても大変。自動でタグ付けするソフトもあるようですが、トレーニングが有料となっていたりします。
トレーニング時間も長い。2種類を判別するモデルでしたが、18時間トレーニングにかかりました。2種類を判別するモデルでは、高精度で判別できていました。その後に、5種類の似た物体を判別するモデルを作成しましたが、精度がとても低く、使えませんでした。
明確に差のある特徴は判別できますが、似たような物体は、難しいです。トレーニング前に準備する画像を増やせば精度は上がるかもしれませんが、個人的な体感として、100枚程度の画像では、画像分類の精度に及びません。
まとめ
いかがたっだでしょうか。画像分類と物体検知のイメージは着きましたでしょうか。
私の体感となりますが、画面内に1つずつ表示して、AIに判別させるのであれば、画像分類の方が、作る手間が少なく、また精度が高いと感じています。物体検知で精度を上げるためには、準備する画像を大量に増やす必要があるのではないでしょうか。(タグ付け作業が途方もないことになりますが・・・)
ですので、AIに判断させる条件次第で、画像分類か物体検知を選択するようになると思います。画面内に1つの物体のみで、物体の位置は関係ないのであれば、画像分類を選択し、複数の物体を同時に検知する場合は、物体検知を選択すると良いと思います。